
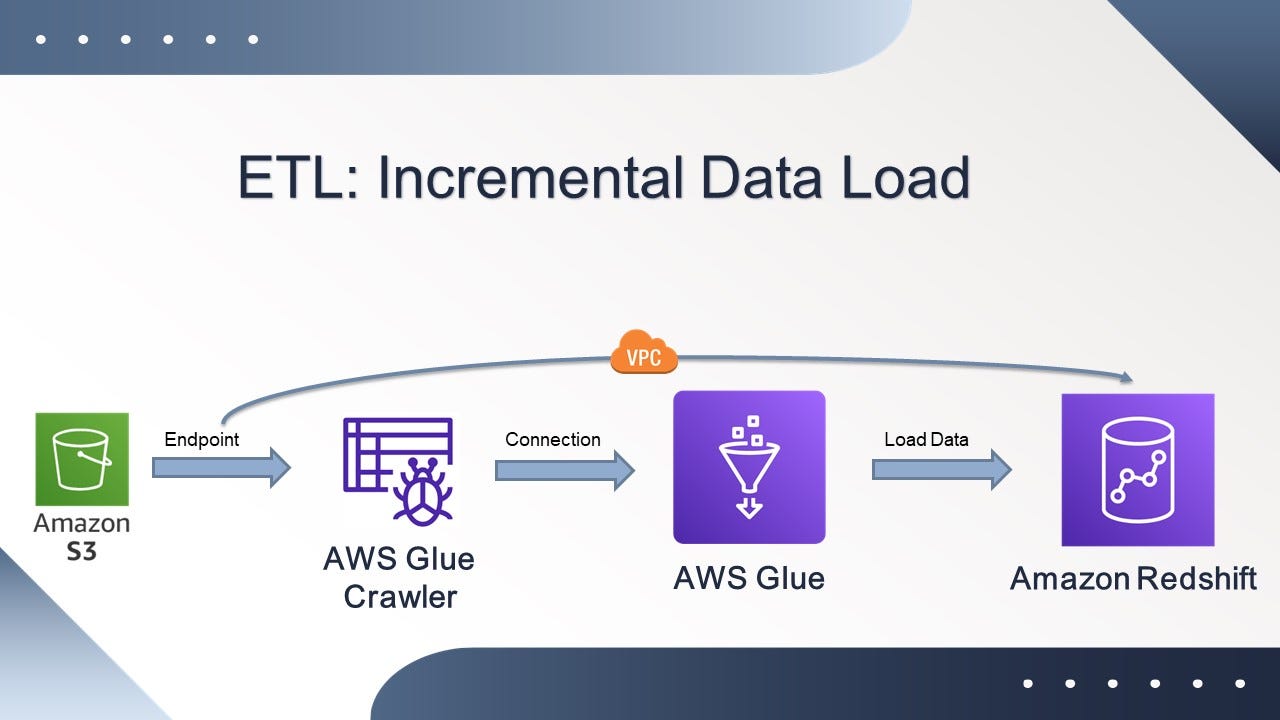
ETL: Incremental Data Load

Performing an ETL Task (Extract, Transform, Load) using Amazon S3, AWS Glue, and Amazon Redshift
This combination of AWS cloud tools allows you to handle large volumes of data efficiently and effectively. It also allows updating or adding new information to the database.
Create an S3 Bucket
In the S3 console, create a new bucket where the relevant files will be uploaded.
Configure an Endpoint in VPC
In the VPC, create an endpoint for the S3 bucket. Select the S3 service with the "Gateway" type and Choose the VPC where Redshift is located.
Create an IAM Role
Create an IAM role with the following permissions:
AdministratorAccess
AmazonRedshiftFullAccess
AmazonS3FullAccess
Configure Amazon Redshift
Set up Amazon Redshift:
Create a Redshift cluster or use the serverless version.
In Query Editor, connect to Redshift and create a table with the columns and data types to be used.
Configure AWS Glue
Create a Database in Glue:
Create a database in AWS Glue.
Create a Crawler in Glue:
Select the S3 bucket where the files are located by specifying the bucket path.
Use the previously created IAM role.
Choose the target database in Glue and optionally a prefix for the table names.
Create a Connection to Redshift in Glue:
Create a connection in Glue to Amazon Redshift.
Select the Redshift database, provide the database name, and credentials.
Run the Crawler:
Run the crawler to automatically obtain the tables.
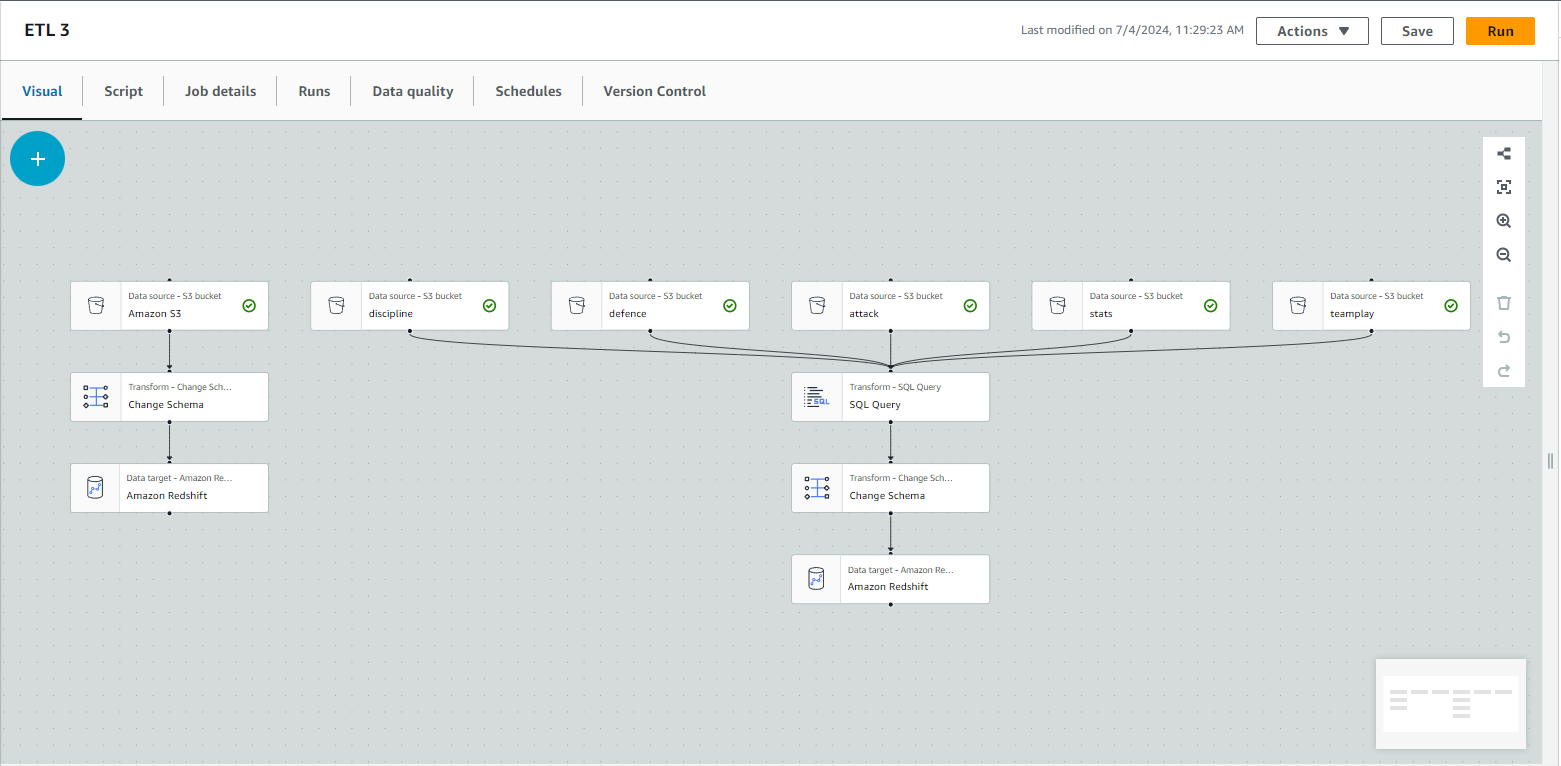
Create and Run an ETL Job in Glue
Create an ETL Job in Glue:
In Glue, select Visual ETL to create the ETL job.
Configure the ETL job to transform and load data from S3 to Redshift.
When selecting the target (Redshift), choose the MERGE option in Handling of data and target table.
Run the ETL job.
Load Data to Redshift
Load Data to Redshift:
Upload the files to the S3 bucket.
Run the ETL job to load the data into Redshift.
Once the data is in Redshift, you can use data visualization tools to analyze the stored information.
Conclusion
This process ensures that data is efficiently moved from S3 to Redshift, using Glue for automation and Redshift for data storage and analysis. By following these steps, you will be able to manage and analyze large volumes of data effectively, making the most of AWS cloud capabilities.